概述
这里记录一下图数据相关的调研结论。下面是图数据库的定义:
A graph database is a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data.
注意,这里只是说了通过 提供类似图的语义查询功能,并没有规定图的存储结构。图数据库的主要优点:
- 更好,更快速的查询和分析;
- 更简单和更自然的数据建模;
- 同时支持实时更新和查询;
- 数据结构的灵活性。
图数据库是所有数据管理系统中成长最快的分类,下面分别从图检索语言和图数据库两个方面来介绍图数据市场的发展。
图检索语言
这里主要对比下面:
- Cypher:Neo4j 的查询语言称作 Cypher,Cypher 是对图形的声明查询语言,使用图形模式匹配作为主要的机制作 图形数据选择(包括只读和变更操作)。Cypher 的声明模式匹配性质意味着可以通过描述想从它那里得到什么查询图形数据。
- SPARQL:面向 RDF(Resource Description Framework)的三元组数据,W3C 标准,无 schema,在研究中应用非常广泛。SPARQL的查询与 RDF 是一致的,RDF 是图,SPARQL 查询是子图匹配。
- Gremlin:数据以属性图的形式存在,属性仍然在表中,但是联接关系是直接以链接(比如指针)的形式存在的。查询的本质是图遍历,擅长解决求图的直径、点到点之间的路径。
各自的特点:
- Cypher:只能在 Neo4j 上使用,但是社区版的Neo4j 只能跑在单机上,用 Gremlin 和 SPARQL 可以很容易地从某个数据库转到另外一个,但Cypher就不要想了。另外,Neo4j 的数据组织是属性图的。
- Gremlin:查询的图本质仍然是一张一张的表,因此处理数据、管理数据相对简单一些。但是有一个比较大的问题是各家对 Gremlin 的实现不一,自动生成代码比较困难,实现的效率也不一样,让人比较头疼。
- SPARQL:W3C 标准,查询语句比较简单,自动生成语义查询也相对容易。另外 RDF 数据本身在数据交换上比较有优势,比如 DBPedia、Freebase 之类的数据都有 RDF 版。
- SQL/ElasticSearch:当然也可以自己构造查询,但是人工把输入抽象到像 SPARQL/Gremlin 这种级别的查询上还是需要一些工作的,本身未必很难,但是得做。
图数据库
下面是一些流行的图数据库及其发展趋势,数据来源于:https://db-engines.com/en/ 。DB-Engines创办于2012年10月,是目前世界上最具权威数据库排行榜。
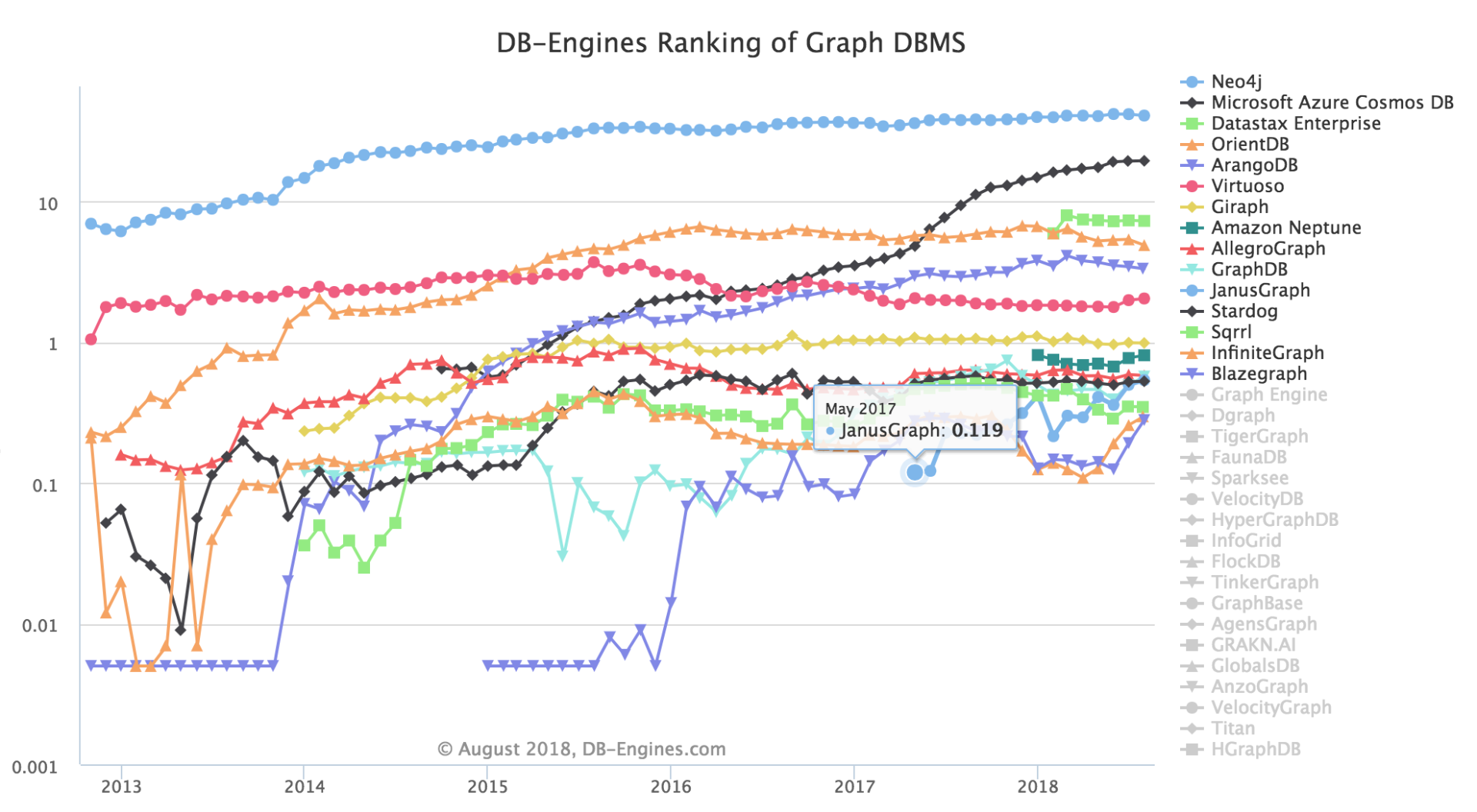
从图中可以获取到的信息有:
- 无论是在 native 图数据库 还是复合型图数据库,Neo4j 均取得了一枝独秀的成绩;
- 微软 Azure 的 Cosmos DB 的增长速度非常非常非常迅猛;
- ArangoDB 是一个多模型的 NoSQL 数据库,同时支持图、kv、document 存储,近几年的热度在持续上升中;
- Titan 自从2015年被 Datastax 收购后,其活跃度大幅下降,因此没有计入2018年的排行榜,其继任者 JanusGraph 也在快速跟进中;
此外一些国内还有一些图开源项目,如 HugeGraph ,将在后面一部分介绍。
图数据库特性对比
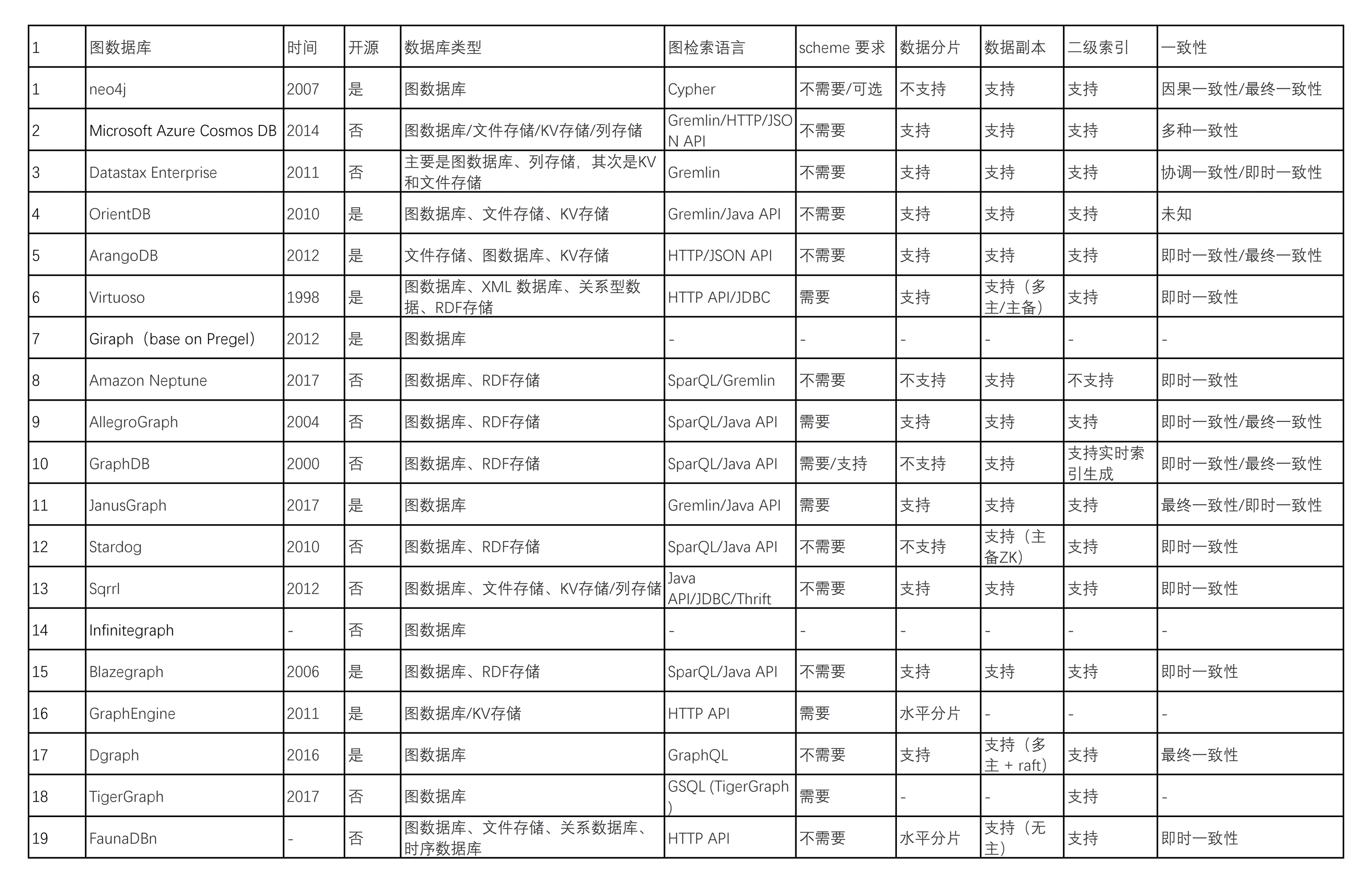
注:图片比较小,可以放大查看。
常见图数据图介绍
Neo4j
Neo4j 是目前最流行的图形数据库,支持完整的事务,在属性图中,图是由顶点(Vertex),边(Edge)和属性(Property)组成的,顶点和边都可以设置属性,顶点也称作节点,边也称作关系,每个节点和关系都可以由一个或多个属性。Neo4j创建的图是用顶点和边构建一个有向图,其查询语言cypher已经成为事实上的标准。
Neo4j 分为社区版和企业版,社区版只能工作在单机上,社区版免费 ,企业版收费 。
Neo4j 的功能就不具体介绍了,只说下它的优缺点吧。
优点:
- 它很容易表示连接的数据;
- 检索/遍历/导航更多的连接数据是非常容易和快速的;
- 它非常容易地表示半结构化数据;
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习;
- 它使用简单而强大的数据模型;
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引。
缺点:
- Neo4j 2.1.3最新版本具有支持节点数,关系和属性的限制。
- 它不支持分片。
Neo4j官方地址:https://neo4j.com/。
Microsoft Azure Cosmos DB
Cosmos DB是微软2010年立项,经过7年研发,于2017年5月正式发布的云数据库服务,该数据库服务支持图数据、列存储、键值存储和文档数据库等多种数据模型,同时支持强一致性和最终一致性,以及介于之间的有边界一致性( Bounded Staleness)、事物一致性(Session)与单调一致性(ConsistentPrefix)。
AWS和微软这两个竞争对手在云数据库的处理方法上截然不同的。AWS提供了多种不同类型的云数据库产品供用户选择,比如:关系型数据库(Aurora / RDS),数据仓库(Redshift),内存数据库(ElastiCache),图形数据库(Neptune)和NoSQL(DynamoDB)。而微软则恰好相反, Cosmos DB采取一刀切的方式,号称可以适用一切通用型数据库。
微软的Cosmos DB的天才之处在于开发人员可能希望在混合持久化方面鱼与熊掌兼得。正如InfoWorld的SerdarYegulalp所写的:“在拥有Cosmos DB的情况下,微软在同一个数据库中提供了多重持久化模型,因此模型的选择可以是工作负载的功能而不是产品的功能”。这是很重要的。
Cosmos DB 的优势:
- 全球部部署
- 多数据模型+API
- 提供了五种数据一致性(参考这里)
- 弹性存储拓展
- …
Amazon Neptune
2017年11月底,亚马逊在 AWS 2017全球峰会发布了全新的图数据库产品:Neptune。Amazon Neptune 支持 Gremlin 和 SPARQL 的开放图谱 API,并为这些图形模型及其查询语言提供高性能。
- 用 Gremlin 查询 Apache TinkerPop3样式属性图。Gremlin 是一种图遍历语言,其中查询是遍历节点边缘之后离散步骤构成的遍历。
- 用 SPARQL 查询 RDF。Neptune支持以下标准:RDF 1.1,SPARQL查询1.1,SPARQL更新1.1和SPARQL协议1.1。
Neptune 的优势:同时支持 SQL 和 Gremlin 检索。
JanusGraph
JanusGraph 是Titan 1.0.0版本的延续,Titan 是从2012年开始开发,到2016年停止维护的一个分布式图数据库。最初在2012年启动 Titan 项目的公司是 Aurelius,2015年此公司被 DataStax(DataStax是开发apache Cassandra 的公司)收购,DataStax 公司吸收了 TiTan 的图存储能力,形成了自己的商业产品 DataStax Enterprise Graph。JanusGraph 继承了 Titan 的全部功能并做了进一步的改进,并支持 Hadoop 2和 Tinkerpop 3.2.3,采用 Gremlin 图查询语言。

JanusGraph 的两个最明显的优势:
- 支持支持实时、数千用户并发遍历图和分析查询图的功能
- 架构是分布式的,可以自由的扩展集群节点的,可以利用很大的集群,JanusGraph 可以存储很大的包含数千亿个节点和边的图。
特别是第二点,这是JanusGraph相较于Neo4j 这种原生图存储最大的优势,Neo4j没法存储巨大的一张关系图 ,因为他不支持分片。
通过两种不同的方式来使用 JanusGraph:
- 可以把JanusGraph嵌入到应用程序中去,JanusGraph和应用程序处在同一个JVM中。应用程序中的客户代码(相对JanusGraph来说是客户)直接调用Gremlin去查询JanusGraph中存储的图,这种情况下外部存储系统可以是本地的,也可以处在远程。
- 应用程序和Janus Graph处在两个不同JVM中,应用通过给JanusGraph提交Gremlin查询给GremlinServer,来使用JanusGraph,因为JanusGraph原生是支持Gremlin Server的。(Gremlin Server是Apache Tinkerpop中的一个组件)。
OrientDB
OrientDB是在2011年发布的新一代分布式NoSQL数据库,能够处理Graph、 Document、 Key-Value、 GeoSpatial 和 Reactive 五种模型,是目前最流行的一款多模型数据库。
在OrientDB中,任何类型的数据都是可搜索的,用户域的建模支持面向对象的概念,可以很容易地扩展。 每个模型不只是一个层,而是共存于一个引擎中。 可选无模式、全模式或混合模式。支持许多高级特性,诸如 ACID 事务、快速索引,原生和 SQL 查询功能。可以 JSON 格式导入、导出文档。
HugeGraph
HugeGraph 是一款面向分析型,支持批量操作的图数据库系统,它能够与大数据平台无缝集成,有效解决海量图数据的存储、查询和关联分析需求。HugeGraph 支持 HBase 和 Cassandra 等常见的分布式系统作为其存储引擎来实现水平扩展。HugeGraph 可以与 Spark GraphX 进行链接,借助Spark GraphX 图分析算法(如PageRank、Connected Components、Triangle Count等)对HugeGraph的数据进行分析挖掘。

HugeGraph的系统架构主要包括存储层、计算层和用户接口层三个功能层次。
HugeGraph 的存储层包括图数据(顶点、边和属性等)存储、索引数据存储和 Schema 元数据存储。HugeGraph 后端存储会采用插件化方案,目前已经支持 RocksDB、Cassandra、ScyllaDB、HBase、Doris(原Baidu Palo)和 MySQL 等,后续会适配更多的后端存储系统。
HugeGraph 的计算层包括 OLTP 和 OLAP 两种类型。其中 HugeGraph 重点实现了 OLTP 核心功能,而OLAP部分功能需要和 Spark GraphX 相结合完成。
关于 HugeGraph 的性能, 其开发者提到:
我们在4组开源数据集分别对HugeGraph、TitanDB和Neo4j进行批量写入性能测试,测试结果如表1所示。HugeGraph采用RocksDB存储引擎时插入amazon0601数据集的300万条边耗时为5.711秒,平均每秒可完成50万条边插入。性能数据分析来看HugeGraph的批量插入性能明显优于Neo4j和TitanDB。
更多信息参考:https://github.com/hugegraph。
总结
几点总结:
- 多存储模式的图数据库技术是目前发展的一个主要趋势,从 Azure Cosmos DB 的发展可以看到(毕竟数据迁移的成本太高);
- 以 JenusGraph 为代表的 NoSQL 存储的分布式图数据日渐火热,由于其存储和查询严重分离,性能提升的空间十分巨大。
- 以 Neo4j 为代表的所谓 native 图数据库,主要特点是查一个点的边或者边上的端点时,不需要再走一次B+树索引,而是直接指针指向下一度的物理地址。它的十字链表结构在内存够大,或者有SSD盘的情况下性能还是不错的,但是存在性能瓶颈。
- TiggerGraph 这个数据库号称是「*首个原生并行图系统,TigerGraph代表了图数据库演进的下一个阶段,它是第一个能够在互联网规模数据上进行实时分析的系统…*」,可以关注一下。